Imagine us in charge of developing a feature to show public data coming from a third party that doesn’t have an API. Let’s say, we need to show current and historical data of dam water level which we can access at http://www.dwa.gov.za/Hydrology/Weekly/ProvinceWeek.aspx?region=WC. We cannot possibly add the entry manually--it’s too time consuming. Some of us might choose the hard way to ask the data provider to make a public API, but there is a time constraint as we need it as soon as possible. One way to solve this is to use a method called “web scraping”.
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. There are few Python libraries available from the simple Beautiful Soup (BS), to advanced Scrapy that also provide scrawling and many more features. In this example, we will use BS4 as we only need basic web scraping.
First, we need to install Requests and Beautiful Soup. We need Requests, as Beautiful Soup only supports parsing the response into HTML/XML, without the ability to make requests to the server.
$ pip install requests beautifulsoup4Getting Web Page with Requests
First, we will use Python shell to understand web scraping line-by-line, then import the Requests library.
$ python3.8
Python 3.8.5 (default, Jul 27 2020, 12:59:40)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information
>>> import requestsWe’ll assign the URI of the page to the variable url, then get that page using Requests.
>>> url = 'http://www.dwa.gov.za/Hydrology/Weekly/ProvinceWeek.aspx?region=WC'
>>> page = requests.get(url)page now contains the source of that url’s page. You can check the source by viewing the source or inspecting the element on the browser. In this example, I will only show you that the status code is OK (200) and the number of characters in the page is huge so we don’t need to print it.
>>> page.status_code
200
>>> len(page.text)
50198
Parsing Page Source with Beautiful Soup
Beautiful Soup (BeautifulSoup) creates a parse tree from the parsed HTML or XML document. Using the previously fetched web page, we will create a Beautiful Soup object that is usually called soup. For the HTML page, we can use Python’s built-inhtml.parser. The object represents the HTML page as a nested data structure.
>>> from Beautiful Soup import BeautifulSoup
>>> soup = BeautifulSoup(response.text, 'html.parser')
Finding HTML Tag
We can easily find a tag from a page using Beautiful Soup’s find_all function. This will return all element within the page.
>>> ps = soup.find_all('p')
>>> ps
[]
That means there is no element with p tag in that page. You can compare the result to the page’s source if want to. As you can see, the square bracket [] indicates that it has Python’s list data-type, thus we can use indexing to access the element. Accessing the text inside the tag can be done using get_text().
>>> all_a = soup.find_all('a')
>>> len(all_a)
161
>>> all_a[3].get_text()
'Download PDF file'
If we want to get only one result, we can use find which will return None for empty result. If there are more than 1 matching elements, it will only return the first one.
>>> div_1 = soup.div
>>> div_2 = soup.find('div')
>>> div_3 = soup.find_all('div')[0]
>>> div_1 == div_2 == div_3
True
They all returns the first div of the page.
Finding Tags by Class and Id
There will be a time when we want to find specific tags. Instead of only using tag, we can also find by class and id. Finding by class is accommodated by the keyword argument class_.
>>> auto_style_class = soup.find_all(class_='auto-style1')
>>> len(auto_style_class)
2
We can also add a tag to it, and it would be
>>> div_class = soup.find_all('div', class_='auto-style1')
>>> len(div_class)
0
We can see there are 2 elements having the class auto-style1, but none has the div tag.
There could be multiple tags and classes throughout the page, but there can be only 1 id on the page. Using id keyword argument, we can find a specific element without the need to add the tag or class.
>>> image1_id = soup.find_all(id='Image1')
>>> image1_id
[<img alt="DWA Home Page" border="0" height="92" id="Image1" src="../Jpegs/dwa_logo.jpg" width="281"/>]
Beautiful Soup features don’t stop here. You can cread the documentation to see more.
Getting an Attribute of an Instance
A Beautiful Soup instance that represents an HTML element has attributes corresponding its HTML counterpart. The a tag for example, has at least the href attribute. We can get the attribute using the get() function.
>>> all_a = soup.find_all('a')
>>> len(all_a)
>>> all_a[0].get('href')
'http://www.dwa.gov.za'
Scraping a Certain Page
After knowing which information we want to extract, we have to understand the page structure. For example, we want to extract Region, Date, Dam, River, Photo, Indicators, FSC, This Week, Last Week, and Last Year. Let’s inspect the web page to better understand the structure.
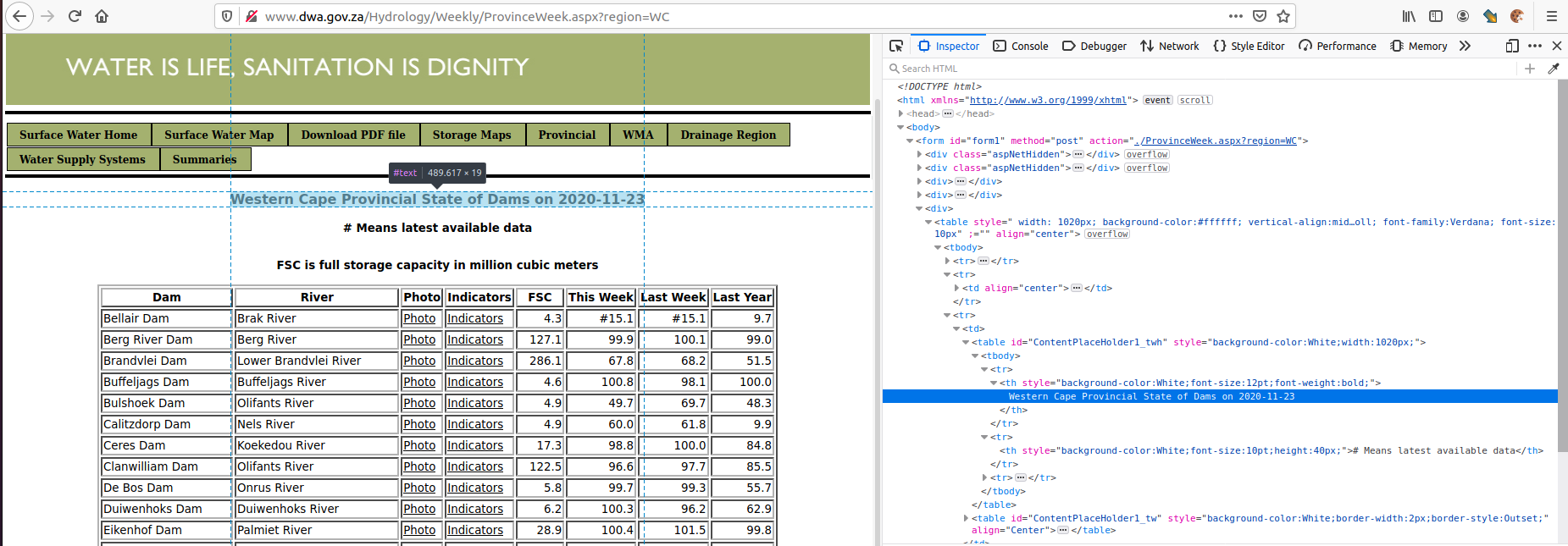
The element containing the Region and Date is the first th of table with id=ContentPlaceHolder1_twh. We can extract the Region and Date using this script.
>>> title = soup.find(id='ContentPlaceHolder1_twh').th.get_text()
>>> title
'Western Cape Provincial State of Dams on 2020-11-23'
>>> date = title.split(' ')[-1]
>>> date
'2020-11-23'
>>> region = title.split(' Provincial')[0]
>>> region
'Western Cape'
Now the more complicated part. Dam, River, Photo, Indicators, FSC, This Week, Last Week, and Last Year are located inside the table. The idea is to loop through all rows of that table, and then process the data.
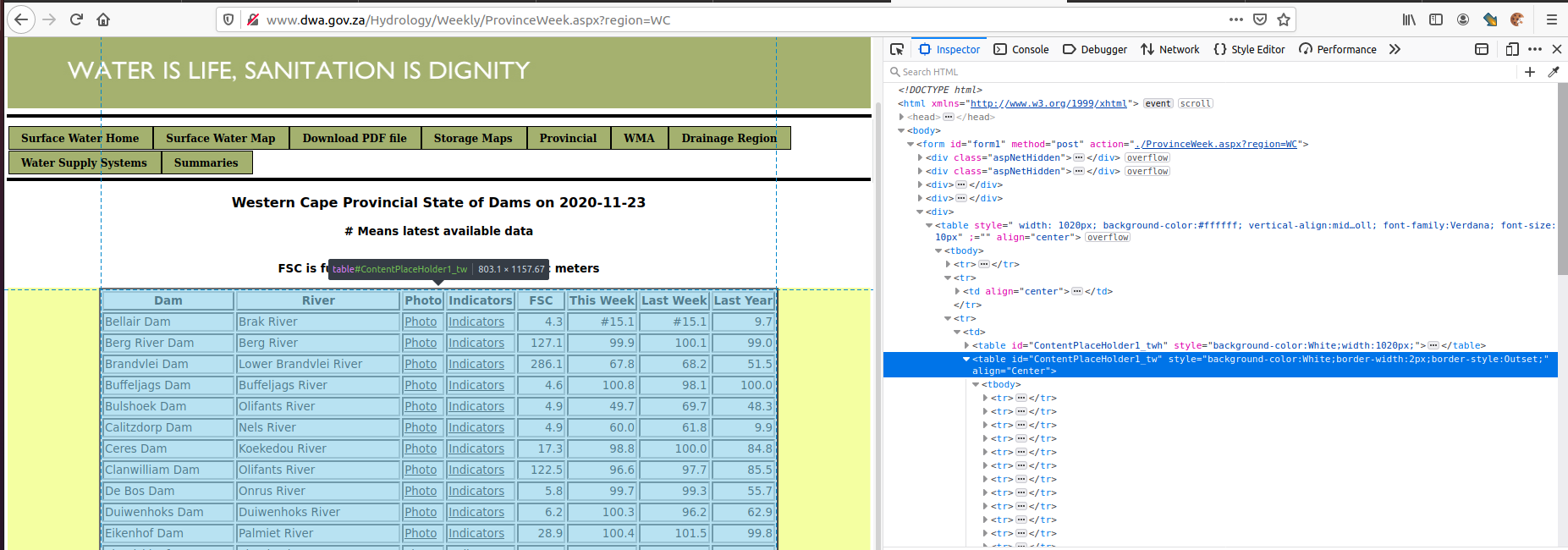
The table’s id is ContentPlaceHolder1_tw. If we scroll down to the bottom, we can see the table has a row containing a TOTAL value, which we don’t want to extract. See the code below
headers = ["dam", "river", "photo", "indicators", "fsc", "this_week", "last_week", "last_year"]
for row in result.find(id='ContentPlaceHolder1_tw').findAll('tr'):
# Explanation 1
if len(row.findAll('td')) == len(headers):
row_data = {
"date": date,
"region": region}
for index, column in enumerate(row.findAll('td')):
# Explanation 2
value = column.get_text().strip()
if headers[index] in ["photo", "indicators"]:
# get Photo Page of the
try:
# Explanation 3
value = column.a.get('href')
except Exception:
value = None
row_data[headers[index]] = value
Explanation 1
We don’t want to extract last row. So, we need to make sure the length of the header matches the number of cells in the row. There are other ways to do it, you can find them on your own and tell us in the comment section.
Explanation 2
We use get_text() to get the text inside the element, then remove the leading and trailing white space with strip().
Explanation 3
Photo and Indicator each contain a link and we want to extract its link value instead of the anchor text. We get a from a cell, and get the href value using get(). We only do simple web scraping here, so we only get the URL of the Photo and Indicator Page which contain image of dam water and graph. In real world, we might want to get the URL of the image instead of the page. You can fiddle with the code to get the URL of the Dam image and Indicator graph.
Now, we need to convert to it to a proper class, so we can integrate it to our application.
import os
import requests
from bs4 import BeautifulSoup
from requests import Response
from typing import Iterator
class Scraper():
headers = ["dam", "river", "photo", "indicators", "fsc", "this_week", "last_week", "last_year"]
domain = "http://www.dwa.gov.za"
url = os.path.join(domain, "Hydrology/Weekly/ProvinceWeek.aspx?region=WC")
def get_page(self) -> Response:
"""
Request specific URL that we want to scrape
:return: response of the URL
:rtype: Response object
"""
return requests.get(self.url)
def get_soup(self, response_text) -> BeautifulSoup:
"""
Create BS4 instance from the webpage.
:param response_text: HTML content of the webpage
:type response_text: String
:return: parsed HTML
:rtype: BeautifulSoup object
"""
return BeautifulSoup(response_text, 'html.parser')
def process_data(self, row_data) -> None:
"""
Process extracted data. We can save it to Django model,
CSV, or simply print it.
:param row_data: Extracted data from table row.
:type row_data: Dictionary
"""
print(row_data)
def scrape(self) -> Iterator[dict]:
"""
Extract data from a webpage.
"""
result = self.get_soup(self.get_page().text)
headers = self.headers
title = result.find(id='ContentPlaceHolder1_twh').th.get_text()
date = title.split(' ')[-1]
region = title.split(' Provincial')[0]
for row in result.find(id='ContentPlaceHolder1_tw').findAll('tr'):
if len(row.findAll('td')) == len(headers):
row_data = {
"date": date,
"region": region}
for index, column in enumerate(row.findAll('td')):
value = column.get_text().strip()
if headers[index] in ["photo", "indicators"]:
# get Photo Page of the
try:
value = column.a.get('href')
except Exception:
value = None
row_data[headers[index]] = value
yield row_data
def run(self) -> None:
"""
Run scraping and process the extracted value.
"""
for data in Scraper().scrape():
self.process_data(data)
if __name__ == '__main__':
Scraper().run()
When we run it, it will print extracted data as we currently define process_data() to only print the extracted data. You can update the function to cater your need, like saving the data to Django model or export it to CSV.
{'date': '2020-11-23', 'region': 'Western Cape', 'dam': 'Bellair Dam', 'river': 'Brak River', 'photo': 'Photo.aspx?photo=J1R002.jpg',
'indicators': 'percentile.aspx?station= J1R002', 'fsc': '4.3', 'this_week': '#15.1', 'last_week': '#15.1', 'last_year': '9.7'}
...
{'date': '2020-11-23', 'region': 'Western Cape', 'dam': 'Wolwedans Dam', 'river': 'Groot Brak River', 'photo': 'Photo.aspx?photo=K2R002.jpg',
'indicators': 'percentile.aspx?station= K2R002', 'fsc': '24.7', 'this_week': '69.7', 'last_week': '65.7', 'last_year': '52.7'}
Cool, isn't it? Now try it. Update the code above to extract the URL of the Photo image and Indicator chart, or start your own web scraping project. Please remember to be considerate when scraping a website as it basically acts like a bot and there’s a possibility that we make repetitive requests. So please make sure we don’t put a heavy load on the server.
Share on Twitter Share on Facebook
Comments
There are currently no comments
New Comment